
Over the past months, we’ve gathered customer feedback and monitored Loki’s performance within our Kubernetes clusters. This process has highlighted recurring performance challenges. To address these, we are rolling out optimizations designed to enhance stability and performance. This post outlines the changes we’re making and the reasoning behind them. If you have any feedback or questions please don’t hesitate to reach out to us.
Background
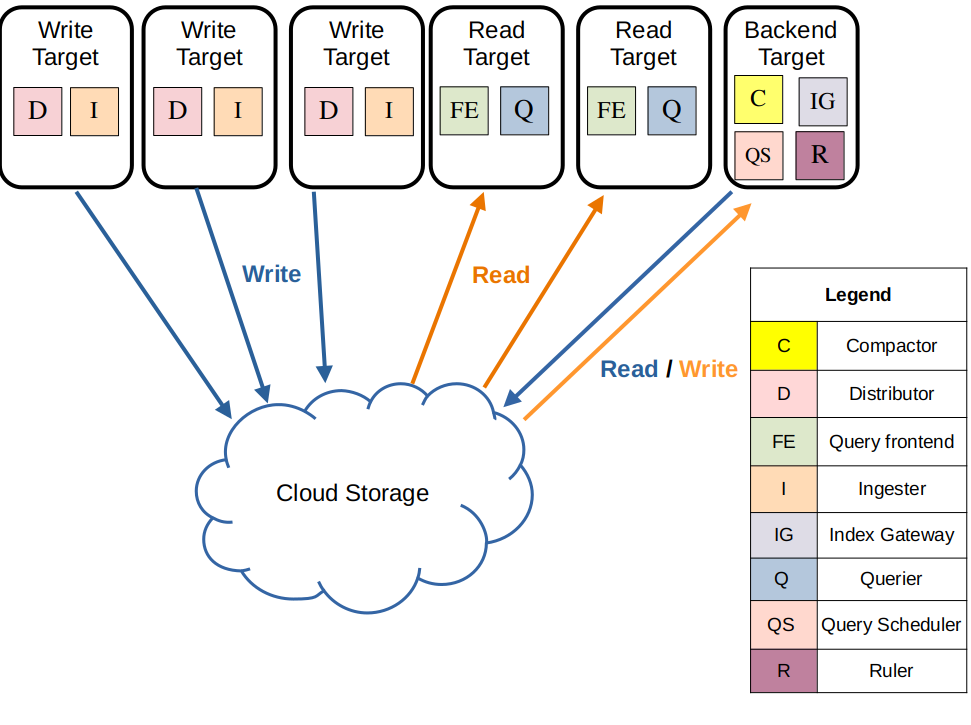
Loki is a log aggregation system inspired by Prometheus that integrates in Grafana. It is designed to be very cost effective and easy to operate. It does not index the contents of the logs, but rather a set of labels for each log stream. We configured Loki in the simple scalable setup meaning we have 3 types of components:
- loki-write: receives logs from applications and writes them to the object store (S3 in our case).
- loki-read: queries the object store to retrieve logs.
- loki-backend: indexes the logs and provides an API to query them.
Common performance issues we have identified
resource requests that are too low, causing the pods to go into OOMKilled state
We have revisited the base resource allocation of the Loki pods to be more in line with the actual usage we have. This should prevent the pods from being killed and offer a more stable environment out of the box. Unfortunately we also notice that the resources needed can vary a lot depending on the usage of the component. Therefore some level of manual tuning will still be needed.
loki-backend pod
In non-production clusters, the loki-backend StatefulSet was configured with only one replica, which proved inadequate to handle log and query loads. While this approach aimed to minimize costs, it became clear that our customers expect higher reliability.
We are increasing the number of replicas to 3. This will allow the loki-backend pods to distribute the load and be more resilient to failures offering a more stable querying experience.
VPA disabled in rare cases
In rare instances, the Vertical Pod Autoscaler (VPA) was found to be disabled. The VPA is crucial for dynamically adjusting pod resource requests based on real-time usage within predefined limits. It ensures that heavily loaded pods receive more resources while underutilized pods scale down to optimize costs without the need for manual intervention.
We now made sure that the VPA is enabled on all clusters and verified the scaling of the loki objects.