
Karpenter is a new big feature that we offer in our AWS reference solution
Today we manage Kubernetes nodes in a classic way through AWS autoscaling groups. However doing it this way brings a couple restrictions, most importantly that nodes are not optimally/automatically matched for the workloads (leaving CPU or Memory unused). Karpenter automatically launches just the right compute resources to handle your cluster’s applications. It is designed to let you take full advantage of the cloud with fast and simple compute provisioning for Kubernetes clusters.
How it works
In Karpenter you can use provisioners to tell Karpenter what constraints it needs to take into account. Depending on how dynamic you configure this provider you allow more flexibility to Karpenter and therefore it can make decisions to launch/terminate instances in order to have the optimal usage of the running instance and therefore save costs. Karpenter also plugs directly into the AWS API to make optimal cost-saving decisions.
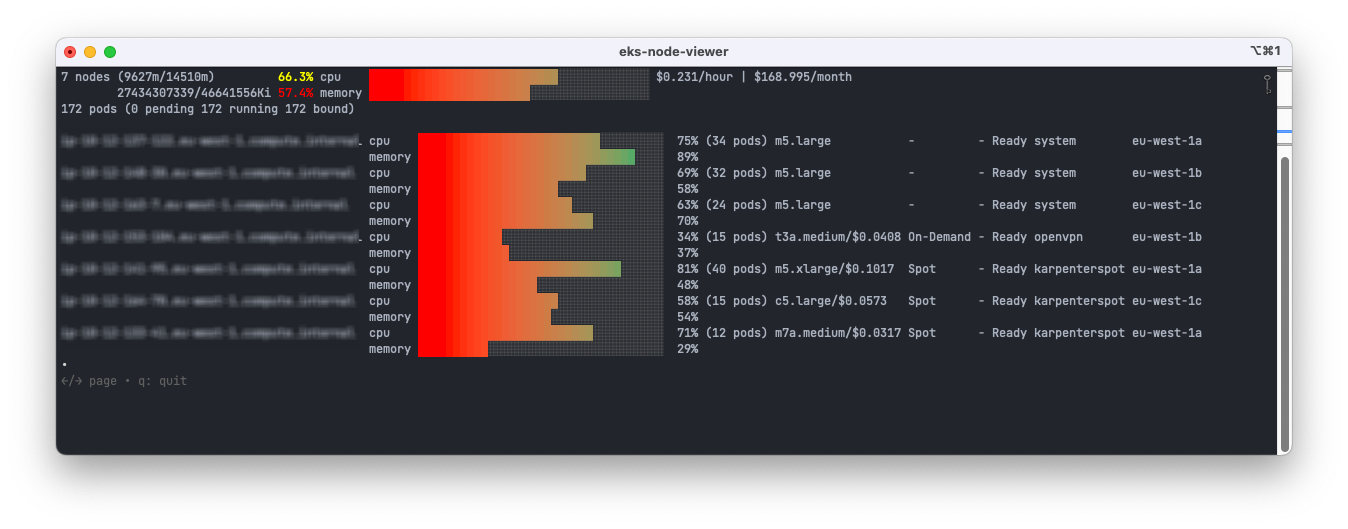
To visualise the node usage and estimated cost on your cluster you can make use of eks-node-viewer:
Requirements
As with all great power comes great responsibility. As you can imagine Karpenter can be quite agressive in moving pods around in order to achieve its perfect state. When pods running on such nodes are not following best practices this could lead to unwanted interruptions of pods and potentially downtime for services running on Kubernetes. Therefore we decided not to fully migrate to Karpenter by default yet.
For more information regarding what is needed for your workloads in order to work together with Karpenter, you can check out the upstream docs and reach out to us. During workshops etc. our team also already tries to teach you many of these practices, like configuring Pod Disruption Budgets.
Next steps
The first version of our implementation is ready for those who want to test it out.
Since there are (possibly) application changes needed to have a stable platform we’ll work with a phased approach on releasing Karpenter.
If you are interested in this feature, please reach out to us via @help and/or by creating a GitHub issue. Once we’ve validated that all requirements are met we can enable this feature for your cluster(s).
Once we have more data on how our customer’s workloads and Karpenter work together, we will proactively reach out to you to assist you in the process to transition the node pools of your cluster(s) to Karpenter.